Introduction
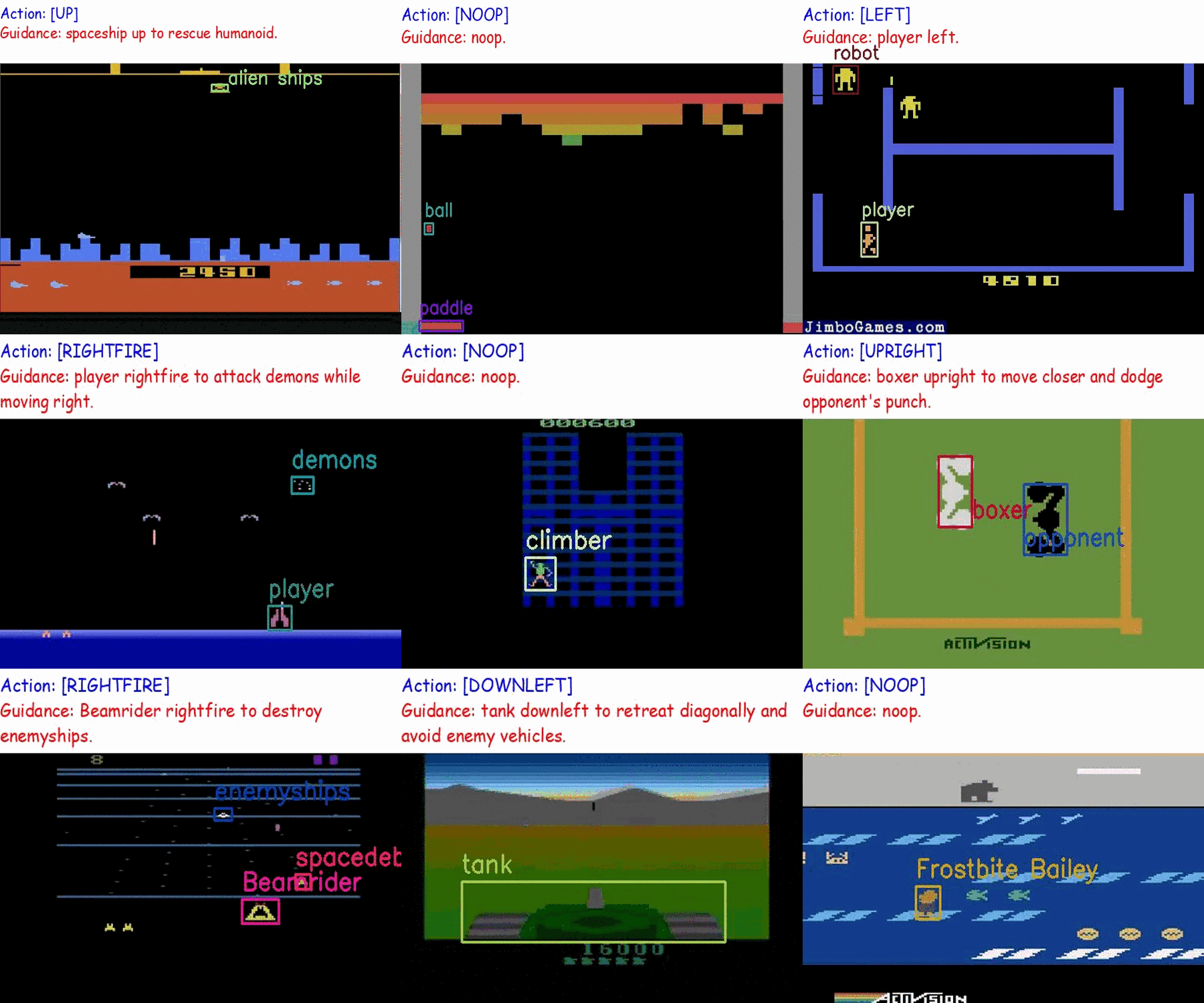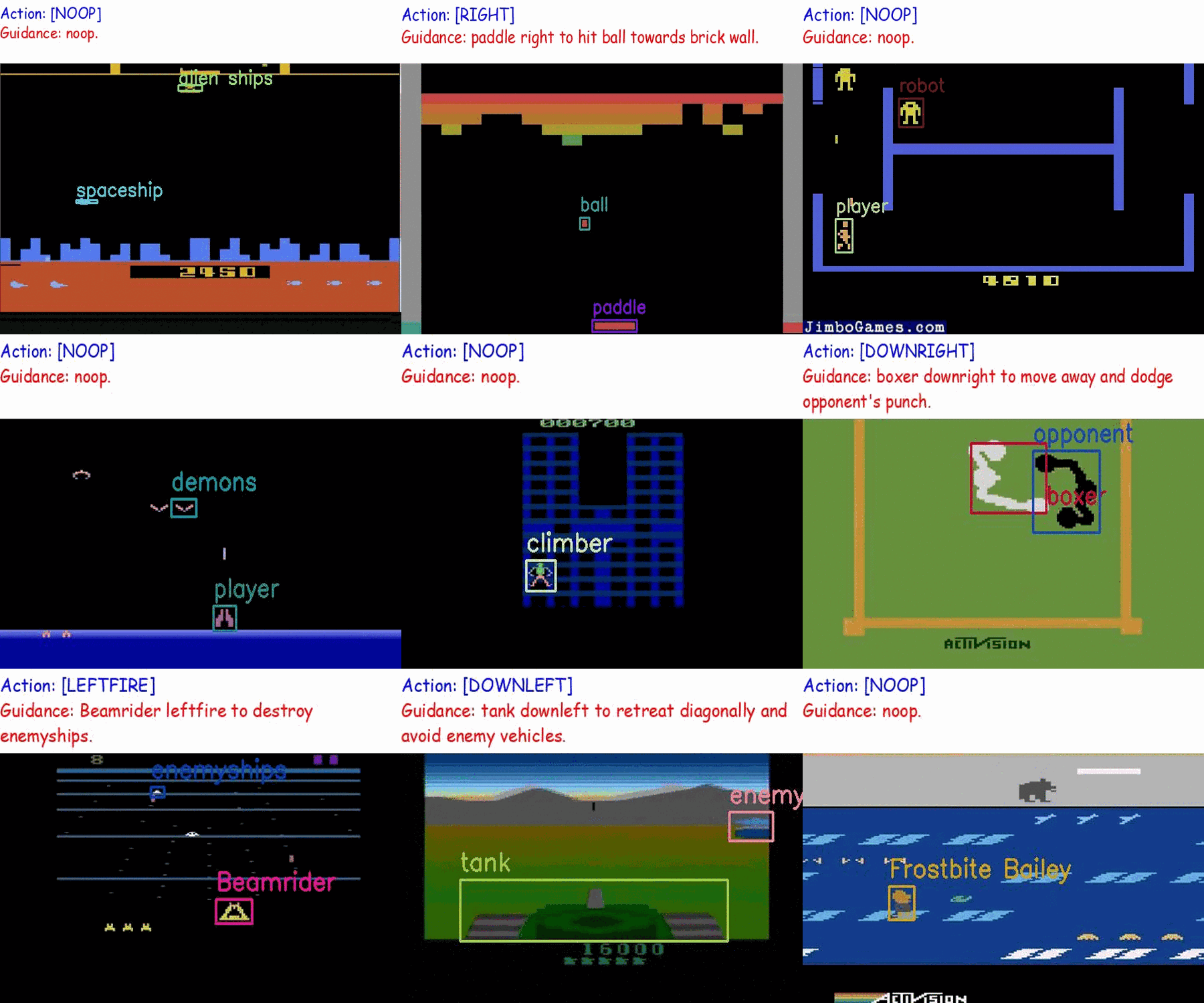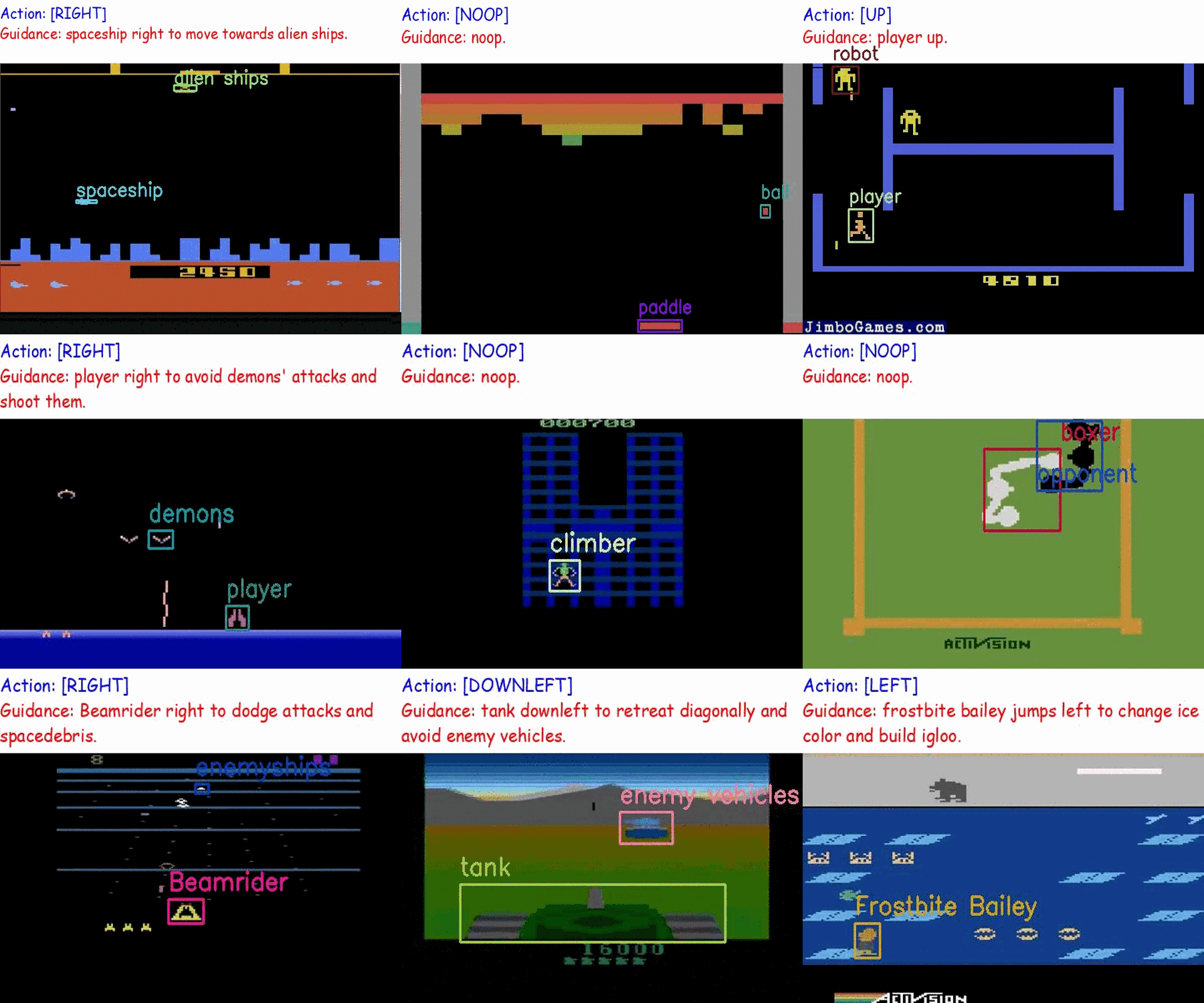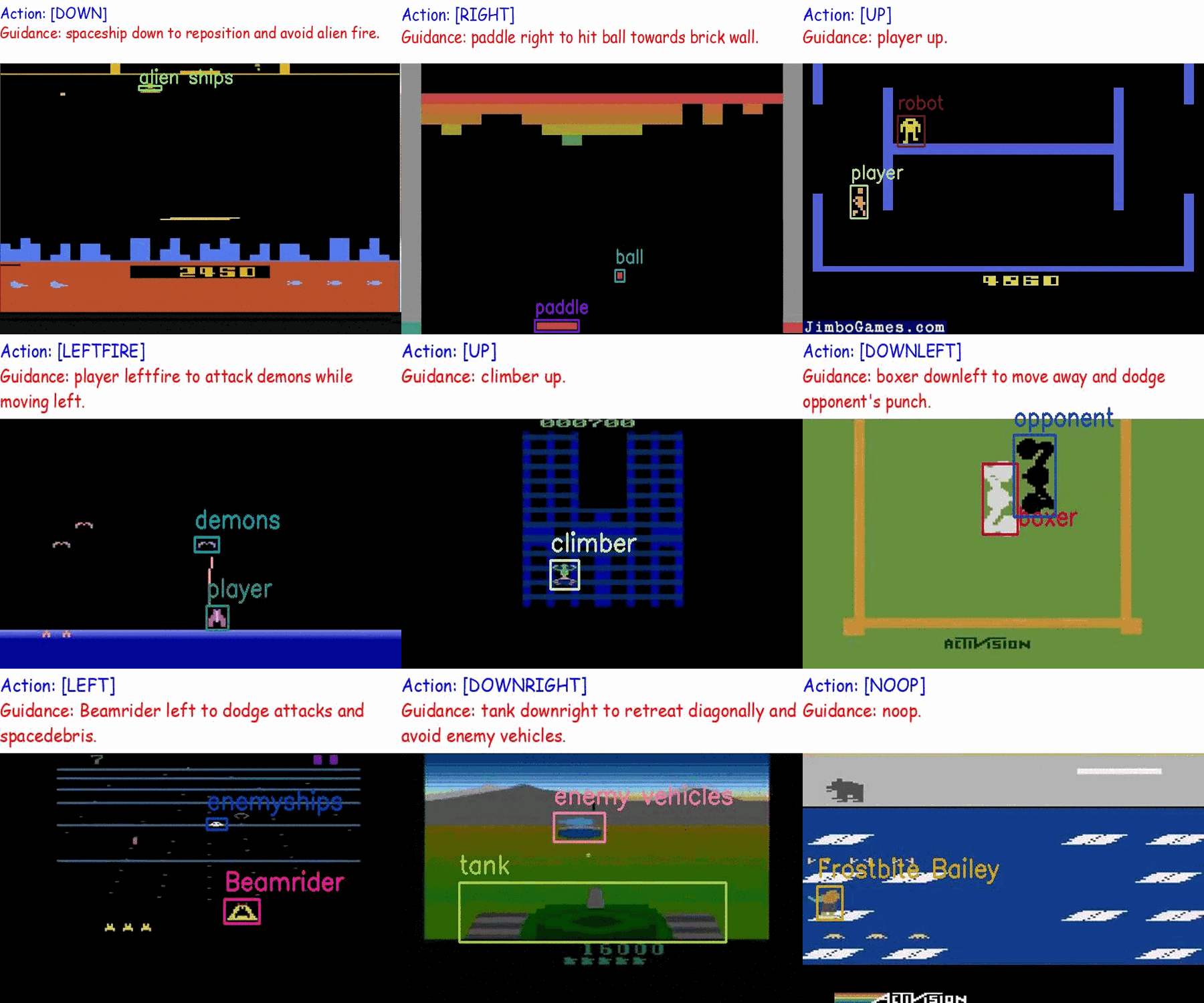
Creating a generalist agent that can accomplish diverse tasks is an enduring goal in artificial intelligence. The recent advancement in integrating textual guidance or visual trajectory into a single decision-making agent presents a potential solution. This line of research provides task-specific context to guide the agent. Although textual guidance and visual trajectory each offer advantages, they also have distinct limitations: (1) Textual guidance lacks visually-grounded information, which diminishes its expressiveness for decision-making tasks based on visual observations; (2) Without clear task instructions, deriving an effective strategy from a visual trajectory is extremely difficult, which is similar to people's difficulty understanding player intentions when watching game videos without explanations. The complementary relationship between textual guidance and visual trajectory suggests their combination enhances guidance effectiveness, as illustrated in Figure 1. As a result, this paper aims to develop an agent capable of adapting to new tasks through multimodal guidance.
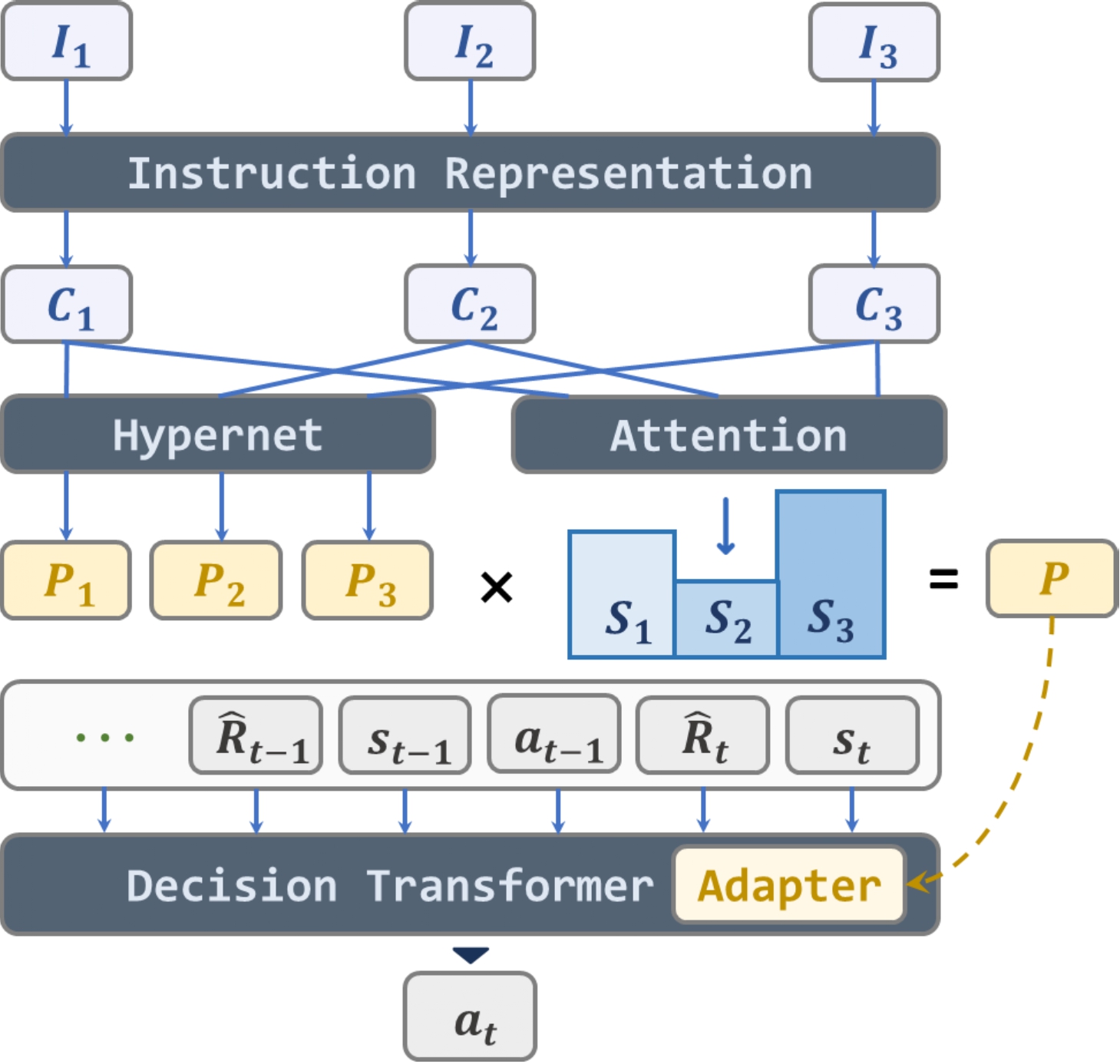
Similar endeavors are undertaken in the field of multimodal models. Drawing inspiration from the success of multimodal instruction tuning in visual tasks, we treat the visual-based RL task as a long-horizon vision task, aiming to integrate it into the RL field. We construct a set of Multimodal Game Instruction (MGI) to provide multimodal guidance for agents. The MGI set comprises thousands of game instructions sourced from approximately 50 diverse Atari games, designed to provide a detailed and thorough context. Each instruction entails a 20-step trajectory, labeled with corresponding textual language guidance. The construction of this multimodal game instruction set aims to empower agents to read game instructions for playing various games and adapting to the new ones.